When it comes to coordinating people around a goal, you don't get limitless communication bandwidth for conveying arbitrarily nuanced messages. Instead, the "amount of words" you get to communicate depends on how many people you're trying to coordinate. Once you have enough people....you don't get many words.

Popular Comments
Recent Discussion
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
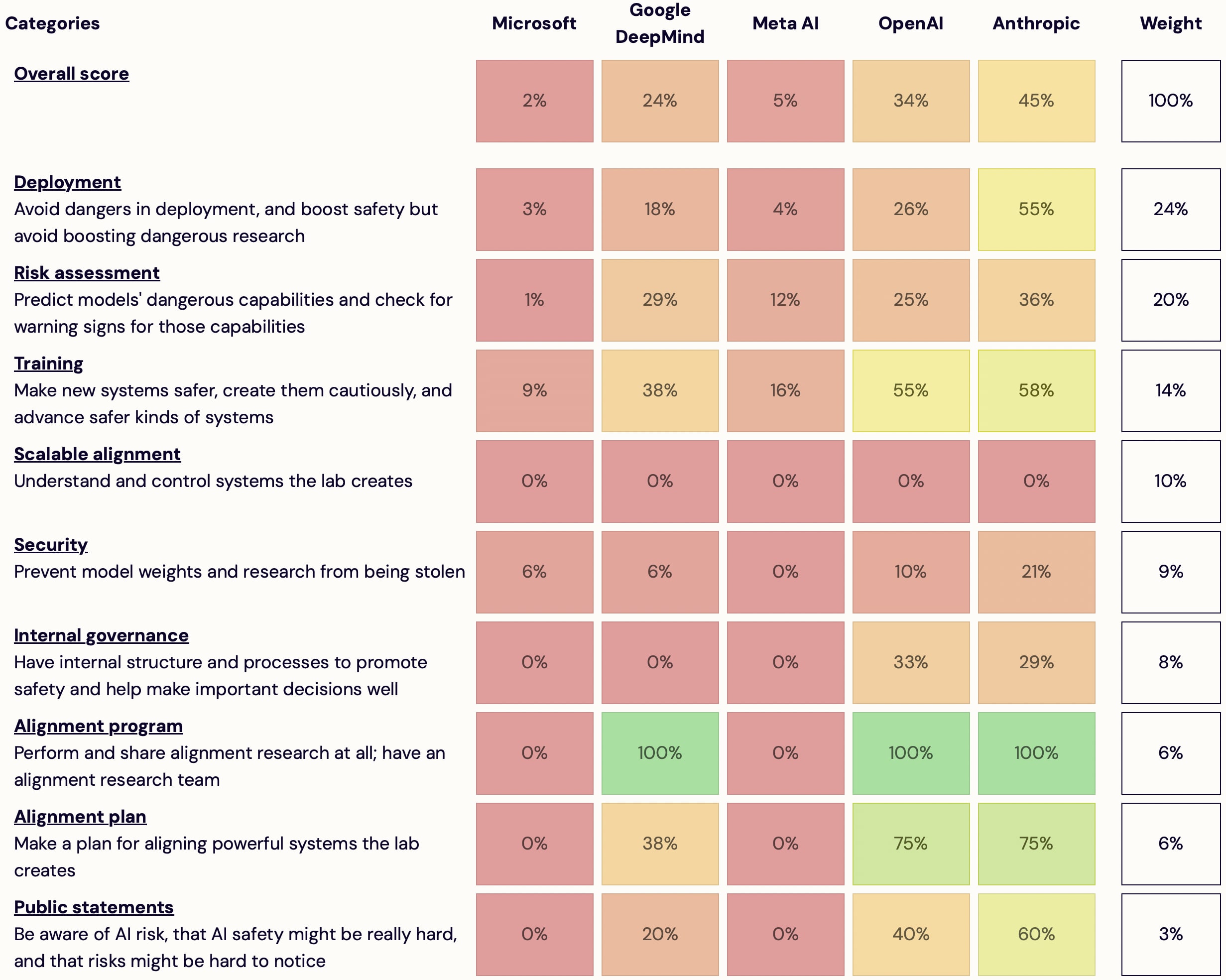
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources
Unfortunately I don't have well-formed thoughts on this topic. I wonder if there are people who specialize in AI lab governance and have written about this, but I'm not personally aware of such writings. To brainstorm some ideas:
- Conduct and publish anonymous surveys of employee attitudes about safety.
- Encourage executives, employees, board members, advisors, etc., to regularly blog about governance and safety culture, including disagreements over important policies.
- Officially encourage (e.g. via financial rewards) internal and external whistleblowers. E
I wrote up a short post with a summary of their results. It doesn't really answer any of your questions. I do have thoughts on a couple, even though I'm not expert on interpretability.
But my main focus is on your footnote: is this going to help much with aligning "real" AGI (I've been looking for a term; maybe REAL stands for Reflective Entities with Agency and Learning?:). I'm of course primarily thinking of foundation models scaffolded to have goals, cognitive routines, and incorporate multiple AI systems such as an episodic memory system. I think ...
Meet inside The Shops at Waterloo Town Square - we will congregate in the seating area next to the Valu-Mart with the trees sticking out in the middle of the benches at 7pm for 15 minutes, and then head over to my nearby apartment's amenity room. If you've been around a few times, feel free to meet up at my apartment front door for 7:30 instead. (There is free city parking at Bridgeport and Regina, 22 Bridgeport Rd E.)
Event
It's been a while since the last one, so I'm running another session of authentic relating games!
Things to expect and prepare for, for those who haven't been to one of these before: edgy questions, physical touch, emotional connection, and a heightened sense of self-awareness. You can of course opt out from any individual game.
For more information, you can check out the Authentic Relating Games Mini-Manual for free on Gumroad, or just message me :)
Linkposting a writeup of my learnings from helping family members augment their investments. I encourage LessWrong users to check it out; I expect the post contains new and actionable information for a number of readers.
Thanks in advance for any comments or feedback that can help the post be more useful to others!
It would be more useful with a little more info on what ideas you're offering. Linkposts with more description get more clickthrough. You can edit in a little more info.
This is the first post in a little series I'm slowly writing on how I see forecasting, particularly conditional forecasting; what it's good for; and whether we should expect people to agree if they just talk to each other enough.
Views are my own. I work at the Forecasting Research Institute (FRI), I forecast with the Samotsvety group, and to the extent that I have formal training in this stuff, it's mostly from studying and collaborating with Leonard Smith, a chaos specialist.
My current plan is:
- Forecasting: the way I think about it [this post]
- The promise of conditional forecasting / cruxing for parameterizing our models of the world
- What we're looking at and what we're paying attention to (Or: why we shouldn't expect people to agree today (Or: there is no "true" probability))
What...
Figure 1 is clumsy, sorry. In the case of a smooth probability distribution of infinite worlds, I think the median and the average world are the same? But in practice, yes, it's an expected value calculation, summing P(world) * P(U|world) for all the worlds you've thought about.
Epistemic status: the stories here are all as true as possible from memory, but my memory is so so.

This is going to be big
It’s late Summer 2017. I am on a walk in the Mendip Hills. It’s warm and sunny and the air feels fresh. With me are around 20 other people from the Effective Altruism London community. We’ve travelled west for a retreat to discuss how to help others more effectively with our donations and careers. As we cross cow field after cow field, I get talking to one of the people from the group I don’t know yet. He seems smart, and cheerful. He tells me that he is an AI researcher at Google DeepMind. He explains how he is thinking about...
I can't recall another time when someone shared their personal feelings and experiences and someone else declared it "propaganda and alarmism". I haven't seen "zero-risker" types do the same, but I would be curious to hear the tale and, if they share it, I don't think anyone one will call it "propaganda and killeveryoneism".
This is a quickly-written opinion piece, of what I understand about OpenAI. I first posted it to Facebook, where it had some discussion.
Some arguments that OpenAI is making, simultaneously:
- OpenAI will likely reach and own transformative AI (useful for attracting talent to work there).
- OpenAI cares a lot about safety (good for public PR and government regulations).
- OpenAI isn’t making anything dangerous and is unlikely to do so in the future (good for public PR and government regulations).
- OpenAI doesn’t need to spend many resources on safety, and implementing safe AI won’t put it at any competitive disadvantage (important for investors who own most of the company).
- Transformative AI will be incredibly valuable for all of humanity in the long term (for public PR and developers).
- People at OpenAI have thought long and
Broadly agree except for this part:
Its in an area that some people (not the OpenAI management) think is unusually high-risk,
I really can't imagine that someone who wrote "Development of superhuman machine intelligence is probably the greatest threat to the continued existence of humanity." in 2015 and occasionally references extinction as a possibility when not directly asked about doesn't think AGI development is high risk.
I'm not sure how to square this circle. I almost hope Sam is being consciously dishonest and has a 4D chess plan, as opposed to ...
This post was written by Peli Grietzer, inspired by internal writings by TJ (tushant jha), for AOI[1]. The original post, published on Feb 5, 2024, can be found here: https://ai.objectives.institute/blog/the-problem-with-alignment.
The purpose of our work at the AI Objectives Institute (AOI) is to direct the impact of AI towards human autonomy and human flourishing. In the course of articulating our mission and positioning ourselves -- a young organization -- in the landscape of AI risk orgs, we’ve come to notice what we think are serious conceptual problems with the prevalent vocabulary of ‘AI alignment.’ This essay will discuss some of the major ways in which we think the concept of ‘alignment’ creates bias and confusion, as well as our own search for clarifying concepts.
At AOI, we try to...
I think you're right about these drawbacks of using the term "alignment" so broadly. And I agree that more work and attention should be devoted to specifying how we suppose these concepts relate to each other. In my experience, far too little effort is devoted to placing scientific work within its broader context. We cannot afford to waste effort in working on alignment.
I don't see a better alternative, nor do you suggest one. My preference in terminology is to simply use more specification, rather than trying to get anyone to change the terminology they u...
Two jobs in AI Safety Advocacy that AFAICT don't exist, but should and probably will very soon. Will EAs be the first to create them though? There is a strong first mover advantage waiting for someone -
1. Volunteer Coordinator - there will soon be a groundswell from the general population wanting to have a positive impact in AI. Most won't know how to. A volunteer manager will help capture and direct their efforts positively, for example, by having them write emails to politicians
2. Partnerships Manager - the President of the Voice Actors guild reached out...
